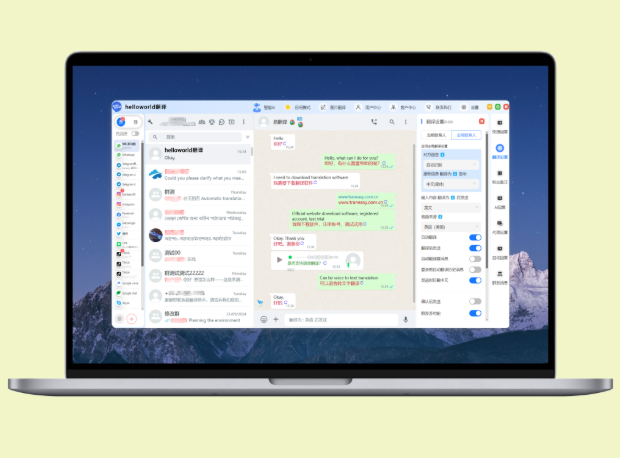
如果你想用 HelloWorld 翻译软件来翻译邮件,通常的做法是:先把邮件正文复制到软件或通过插件导入邮件/附件,选择源语和目标语、翻译模式(即时/文档/邮件专用)、是否保留格式与术语表,然后执行翻译并在预览中逐段校对语气与专有名词,必要时使用人工后编辑或术语管理。遇到批量邮件就用批处理功能并导出带原格式的结果,若有隐私顾虑则开本地翻译或企业加密传输,最后把翻译结果粘回邮件客户端或通过插件一键发送。下面我会一步步拆开讲清楚细节、案例、常见问题和实操模板,带点使用心得,顺便说说那些容易忽略的小地方。

先弄明白:邮件翻译的目标是什么?
别急着点“翻译”,先想想你要达成的目标。是要准确传达技术细节?还是要保持语气和礼貌?又或者只是快速理解大意?不同目标决定不同流程与工具设置:
- 理解邮件大意:机器翻译快速足够,用“阅读模式”。
- 回复与正式沟通:需要术语一致、语气合适,推荐“机器翻译 + 人工润色”。
- 批量客户邮件处理:要保证格式与自动化,优先考虑批处理、API 或插件集成。
- 保密或法律相关:选择本地部署或企业加密,并有审计日志。
一步到位:用 HelloWorld 翻译邮件的实操流程(简洁版)
下面是一个常见且稳妥的工作流,适用于大多数用户:把步骤想成厨房做一道菜,每一步都有工具和调味——少一个,味道就差一点。
准备阶段
- 在邮件客户端(如 Gmail、Outlook)确认邮件是否含附件、HTML 格式或嵌入图片;
- 备份原文,尤其是法律、合同类邮件;
- 在 HelloWorld 中选择翻译任务类型(“单封邮件”“批量邮件”“文档”),并上传或粘贴邮件内容;
- 设定源语、目标语、行业词库与术语表(如公司专有名词);
- 选择是否保留原始排版、是否启用机器+人工后编辑(MTPE)。
执行翻译
- 点击翻译并在“预览”窗口逐段校对;
- 对关键段落(如承诺、数字、时间、金额)逐句核对;
- 如果邮件含表格、代码或合同段落,优先使用“文档模式”以保留格式;
- 对外文名、品牌与专有术语启用术语锁定或映射规则,避免被误译。
后处理与发送
- 将翻译结果导出为纯文本或保留 HTML 的格式;
- 在邮件客户端中粘贴或通过插件一键替换原文;
- 在发送前再次读一遍确认语气——商务邮件常需更礼貌正式,口语邮件可以轻松些;
- 如需多人审阅,使用评论功能或导出可编辑文件交同事校对。
实用设置详解(按功能拆解,像分解机器一样理解)
源语与目标语选择
这看起来很简单,但要注意两点:一是自动检测并不总是准确(尤其是夹杂多种语言的邮件),二是变体选择很重要(中文:简体/繁体;英语:美式/英式)。在 HelloWorld 里,手动确认或锁定语言可以避免奇怪的混译。
保留格式 vs 清除格式
保留格式适合发票、表格、合同等;清除格式适合快速理解或在不同邮箱间粘贴。选错会导致段落错位、链接丢失或样式错乱。
术语表与记忆库
为常用公司名、产品名、专业术语建立术语表可以大幅提高一致性。建议:
- 把公司内部术语上传到 HelloWorld 的术语管理;
- 对行业术语设置首选译法;
- 定期审查术语库,避免老旧翻译持续遗留问题。
具体示例:三种常见邮件场景和翻译模板
场景一:客户询价(商务正式)
思路是准确、礼貌、明确交付信息和下一步。
- 原文重点:产品型号、数量、交货期、付款条款;
- 翻译策略:严格保持数字、单位、日期格式,并用正式语气(如“敬请告知”→“Please advise”);
- 模板(可直接在 HelloWorld 后编辑):
- 开头:感谢来信并确认询价详情;
- 中段:列出报价项、交付期与有效期;
- 结尾:提供联系方式并表达希望合作的意向。
场景二:技术支持邮件(含代码或参数)
这里最怕数值、配置被自动格式化或翻错词。
- 把代码段或命令用“原文保留”或“代码块”功能处理;
- 对参数名、变量名设为术语或不翻译;
- 预览时重点看数字、版本号和路径是否被篡改。
场景三:跨文化社交(轻松语气)
无需逐字直译,更重要是保留幽默与语气。
- 选“文体转换”或“本地化”模式;
- 可允许适当意译以保持自然表达;
- 校对时关注习惯用语与礼貌程度。
表格:功能模式对照(快速查看)
| 模式 | 适用场景 | 注意事项 |
| 即时翻译 | 快速理解邮件大意 | 速度快,但术语一致性差 |
| 文档/邮件保真 | 带表格、合同或 HTML 邮件 | 保留格式但处理复杂,注意图片和链接 |
| 机器+人工润色(MTPE) | 正式对外邮件、法律文件 | 成本与时间较高,但质量最好 |
插件与集成:把翻译嵌到工作流程里
如果你每天都要处理邮件,别每次都手工复制粘贴。HelloWorld 通常有以下集成方式:
- 邮箱插件(Gmail、Outlook):可在阅读邮件时直接调用翻译并粘回回复;
- API 集成:适合企业级批量处理,能接入 CRM、工单系统;
- 桌面客户端或本地代理:在本地环境做翻译,适合高隐私需求;
- 浏览器扩展:适合快速翻译网页版邮件或跨平台使用。
配置插件时要注意权限设置,授权过度可能带来隐私风险。
质量控制:怎么判断翻译“合格”?
不要只看一句话流不流畅,更要看信息是否等价。三个简单维度:
- 准确性:术语、数字、日期等是否保留原意;
- 自然度:目标语读起来是否符合母语者表达习惯;
- 一致性:同一术语在邮件集中是否统一翻译。
推荐做法:先用机器翻译,再按优先级人工校对(关键邮件人工全部校对,普通邮件抽检)。
常见问题与解决方案(像在帮朋友 debug)
- 邮件断行或换行错乱:使用“保留段落”或导出 HTML 模式,检查是否有软换行字符;
- 乱码或字符集问题:确认源文件编码(UTF-8 最保险);
- 附件(PDF、图片)无法翻译:用 OCR 功能提取文本,再翻译,注意校对识别错误;
- 名词被错译:将其加入术语表并锁定为不翻译或固定译法;
- 机翻风格生硬:启用“本地化/口语化”模式或安排人工润色。
隐私与合规性须知
邮件里常有敏感信息:合同、身份证号、财务数据。处理这类邮件时:
- 优先选用支持本地部署或企业私有云的 HelloWorld 版本;
- 启用传输层与存储加密,并检查服务商的数据保留策略;
- 在上传前模糊化或脱敏不必要的敏感字段;
- 保留审计记录,便于事后追溯和合规检查。
实战技巧(那些容易被忽略的小招)
- 先翻要点,再整段:先把关键句(如要求、时间、金额)翻译准确,再处理陪衬句,效率更高;
- 用占位符保护变量:把邮箱地址、链接、产品编号先替换成占位符,翻译完再替换回来;
- 批量处理也要抽检:再精确的术语库也会漏掉边缘案例,随机抽检能发现系统性错误;
- 多语言邮件优先拆分:遇到夹杂多种语言的邮件,分段按语言分别翻译更稳妥;
- 保存翻译记忆:长期项目把翻译记忆库导出备份,便于迁移与恢复。
常见误区(别犯这些低级错误)
- 以为“机器翻译就够了”——正式商务场景不建议直接发送未经校对的机翻;
- 忽略行业差异——同样一句话在不同领域有不同译法;
- 放任翻译软件随意替换专有名词——会导致合同漏洞或误导客户;
- 一次性批量替换而不备份原文——回滚困难且风险大。
如果遇到问题,按这个顺序排查
- 确认原文是否完整(附件、图片、编码);
- 检查 HelloWorld 的语言与模式设置;
- 查看术语库是否覆盖关键词;
- 用小样本测试不同模式(即时、文档、MTPE)对比效果;
- 必要时联系技术支持并提供最小复现样本。
把这些模板拿去用(实用句式示例)
下面给出几句常用的对外邮件翻译句式,你可以直接在 HelloWorld 后做微调:
- “感谢您的来信,我们已收到并正在处理。” → “Thank you for your email. We have received it and are processing your request.”
- “请在 3 个工作日内回复,以便我们安排发货。” → “Please reply within 3 business days so that we can arrange shipment.”
- “附件为报价单,报价有效期为 30 天。” → “Please find the attached quotation. The quotation is valid for 30 days.”
- “如需更多信息,请随时联系我。” → “If you need further information, please feel free to contact me.”
最后一点个人经验(像老朋友提醒你)
刚开始用 HelloWorld 翻邮件时,别急着把所有邮件都自动化。先选一小部分典型邮件做模板和术语表,确认流程后再扩大规模。这样你会发现,工具带来的效率提升是慢慢累加的,而不是一蹴而就的。你会碰到各种小怪癖:某个客户习惯非正式用语、某种附件在不同邮箱呈现不一,这些都需要人去调教工具,像养一台有脾气的机器一样。