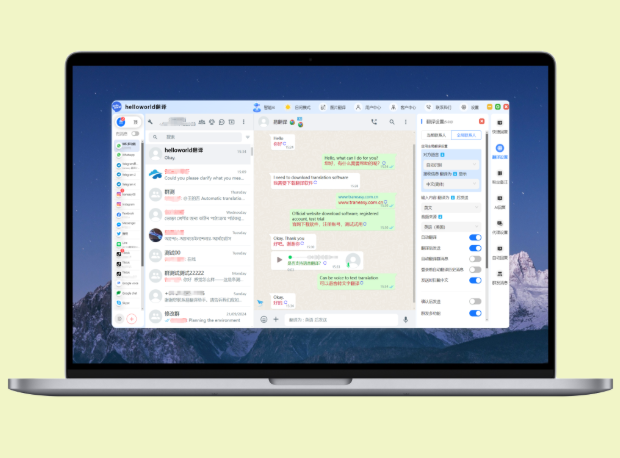
要想把HelloWorld团队的共享话术设置好,先明确目标场景和目标受众,统一风格和口吻;接着建立分类清单和术语库,编写可变换的模板与变量占位符;设立严格的审核、翻译与本地化流程,确保多语言版本的一致性;建立版本控制与变更日志,指定发布渠道;安排培训与定期复盘,依据用户反馈持续迭代。

HelloWorld作为一个基于人工智能的全能翻译伙伴,话术共享并不仅仅是把一段话写得“好看”,而是要让每个团队成员在不同场景下都能快速找到可用的表达,保持品牌声音的一致性,同时兼顾不同语言的礼貌、文化差异与专业性。本文从费曼写作法的四个阶段出发,把复杂的流程讲清楚,并给出可执行的落地方案,帮助团队把共享话术从纸面变成每日工作中的自然助手。
一、用费曼法把思路讲透:把复杂变简单
费曼写作法核心在于把概念拆解成最简单的语言,再把知识“教给新人”,找出自己理解中的空白,反复打磨。对共享话术而言,第一步是把“共享话术到底包括哪些要素”讲清楚,第二步是把具体实现步骤变成新人也能照做的操作清单,第三步是暴露那些容易被忽视的环节(如本地化、术语统一、版本控制),第四步是把整套方法再度简化成一份易于执行的手册。用这样的思路,我们不是把痛点讲清,而是把日常工作中的每一步变得直观、可执行。下面的章节就是按照这条思路展开的。
二、建立框架:场景、风格、语言与角色
- 场景分类:将话术按业务场景划分为常见问答、售前引导、技术支持、售后关怀、跨平台沟通等大类。每类下再细分到具体场景,如“订单查询”、“退货流程”、“支付失败”等。
- 统一风格与口吻:建立一个风格矩阵,覆盖亲和力、专业度、正式度、紧急性等维度。确保不同语言版本在同一情感强度下传达一致的品牌声音。
- 角色与权限:设定谁负责新增、谁负责审核、谁有发布权。明确不同角色在术语库、模板库、知识库中的权限边界,避免重复修改与冲突。
2.1 场景分类的落地做法
- 为每个场景建立“模板集”和“可选项表”,模板是固定框架,可选项是根据情境替换的表达。
- 设定不同语言版本的曲线:常用语言优先走标准模板,边缘语言进行逐步对齐。
- 为紧急场景(如安全告知、交易异常)设立“高优先级模板”,并附带快速审核入口。
2.2 统一风格与口吻的落地做法
- 制定口吻表,包含语气强度、用词偏好、是否使用缩略语、编号格式等。
- 建立“同义表达库”,确保不同语言版本之间的表达在同一语境下等效。
- 提供“模板样式模板”,让新成员一眼就能看懂结构、占位符、替换逻辑。
2.3 角色与权限的落地做法
- 设定审签流程:起草—内部自审—跨语种审核—合规检查—发布。每个环节有截屏证据与变更日志。
- 建立版本号体系:如 v1.0、v1.1、v2.0,标注变更摘要、影响范围与回滚方案。
- 明确责任人:新模板的提出人、语言团队的审核人、平台发布人、客服运营的反馈接收人。
三、模板设计与变量管理:让模板会说话
模板设计是共享话术的核心。它不是简单的占位符拼接,而是以结构化思维把语言的可变部分和不可变部分分离,让不同语言版本都能保持同样的表达逻辑。
3.1 模板结构模型
- 固定部分:包含开场白、问题陈述、行动指引、落地承诺等不可变信息。
- 变量部分:如客户名、订单号、时间、语言偏好等需要动态替换的内容。
- 替换逻辑:明确同义词替换、地域化表达、礼貌等级的切换规则。
3.2 变量占位符与替换策略
- 使用统一的占位符命名,如 {customer_name}, {order_id}, {time_zone}。
- 为不同语言准备等价占位符,确保翻译后仍然可读。
- 设定替换优先级:如若某变量缺失,回退到通用表达,避免断句错乱。
3.3 同义表达与风格控制
- 建立同义表达表,确保在不同语言下仍保持相同情感强度。
- 对技术术语给出明确翻译或保留原文的规则,以免造成混淆。
3.4 模板示例与落地模板库
下面给出一个简化的模板示例,帮助理解结构与替换逻辑。实际库应包含上百条模板,覆盖不同场景与语言。
| 模板名称 | 适用场景 | 固定部分 | 变量占位符 | 替换逻辑 | 版本 |
| 问候开场 | 跨境电商咨询 | 您好{customer_name},感谢您联系HelloWorld团队,我们来帮助您解决问题。 | {customer_name} | 若无客户名,使用“尊敬的朋友”替代;若语言为英文,直译模板结构 | v1.0 |
| 订单查询指引 | 订单状态查询 | 您好,请提供订单号{order_id},我将为您查询最新状态。 | {order_id} | 若无订单号,提示收集信息并自动触发自助查询入口 | v1.0 |
四、术语库与本地化工作流:让术语不再乱跑
术语库是翻译质量的基石。它确保同一概念在不同语言中使用一致的词汇和表达,避免术语混乱导致用户困惑和客服重复沟通。
- 术语统一:建立主术语表、同义词表、禁用词表,明确每条术语的语言版本、应用场景、推荐翻译。
- 本地化工作流:确定翻译-润色-本地化审校的顺序,设定时限与责任人,确保上线前经多轮检查。
- 跨语言一致性:对比不同语言版本的同一场景,确保表达风格、情感强度和信息传达一致。
五、审核、合规与安全:底线要守好
- 内容审核:对涉及隐私、支付、个人信息的对话模板设立额外审核环节,确保信息披露合规。
- 隐私保护:遵循区域性法规,尽量使用占位符替换敏感信息,防止数据在渠道间泄露。
- 安全语言:避免在模板中出现可能被误解的语气、暗示性表述或未授权的承诺。
六、版本控制与发布流程:有据可追的改动
- 版本号与变更日志:每次更新都要记录变更原因、影响场景、涉及语言、发布日期。
- 发布渠道:把模板库放在统一的知识库或协作平台,设定每次变更的审批人和可见范围。
- 回滚方案:若新版本出现问题,提供可快速回滚到前一个稳定版本的流程。
七、培训、落地与迭代:让新人成为高手
培训不是一次性,而是持续的过程。新成员需要尽快理解模板结构、术语库、审核流程以及实际对话中的应用。通过“看-学-做-复盘”的循环,让_shared话术_成为日常工具,而不是额外负担。
- 入职培训:讲解框架、演示模板的使用、给出常见场景的对话示例。
- 定期复盘:每月对本地化质量、用户反馈、错误率进行复盘,明确改进点与负责人。
- 反馈机制:建立简短的反馈表,让客服和运营能快速提交对模板的改进建议。
八、监控与评估:用数据讲道理
- 关键指标:准确度、用时(平均响应时间)、转化率、用户满意度、跨语言一致性分值等。
- A/B测试:对新旧模板做对照,观察对话质量和用户留存的影响。
- 持续改进:将监控结果转化为具体改动,形成下一个版本的迭代计划。
九、实操清单与模板示例:把纸上的方案落到地上
以下是一份可直接执行的实操清单。你可以把它贴在团队工作区,逐条勾选完成情况。
- 确定核心场景与目标语言版本,建立基本模板集。
- 建立术语库,收集常见概念的翻译与同义表达。
- 设计模板结构与变量占位符,制定替换规则与回退策略。
- 建立审核流程,指定责任人与时间线。
- 实施版本控制,记录变更日志与发布计划。
- 开展培训与试用,收集第一轮用户反馈。
- 监控关键指标,进行第一次迭代。
十、常见问题与解答
- Q:如果某语言缺乏专业术语的统一翻译怎么办? A:优先使用术语库中的标准翻译,同时在模板中标注原文或说明,以便后续润色和跨团队对齐。
- Q:新成员如何快速上手模板库? A:提供一份“快速上手手册”,包含模板结构图、常用变量、常见场景示例,以及一张一页纸的操作流程。
- Q:如何确保多语言版本的表达一致性? A:建立跨语言对照表与定期对齐会,使用同义表达库、保持相同情感强度和沟通节奏。
- Q:遇到紧急变更该如何处理? A:设立高优先级变更通道,允许快速启用临时模板,待正式版本完成再回归。
十一、致用心得:把话术变成生活中的好帮手
当你把框架、模板、术语库和审核流程串联起来后,团队的沟通就像日常对话一样自然。这并不意味着没有细节需要关注,而是你已经把复杂的流程拆解成易于执行的小步骤。在这条路上,最重要的不是一蹴而就的完美,而是持续的微小改进与对新情境的快速适应。 HelloWorld团队的共享话术,正是在这种不断迭代的边走边看中,逐渐成为全球用户跨语言沟通的稳固桥梁。
| 要点 | 落地要素 | 注意事项 |
| 目标与场景 | 清晰的场景分类、目标语言 | 避免场景混乱,定期审视分类的完整性 |
| 模板与变量 | 固定结构、可变部分、替换规则 | 变量缺失时的回退策略要明确 |
| 术语库 | 主术语、同义表达、禁用词 | 定期更新,确保跨语言一致性 |
| 审核与发布 | 多级审核、版本控制、变更日志 | 保持透明,避免未记录的修改 |
文献方面的参考可以细究《百度质量白皮书》中的内容管理与知识库建设章节,以及行业常用的术语本地化规范(如跨语言一致性与风格指南的研究材料)。如果你愿意进一步深入,可以查阅相关的知识管理与语言技术研究资料,这些材料能帮助你在实践中更好地把理论转化为产品化的流程。
把这套方法用在HelloWorld团队的实际场景里,你会发现话术不再只是文字的集合,而是一套能被全球合作者快速理解、灵活应用的可操作工具。每一次对模板的微调、每一次术语库的更新、每一次审核与发布的迭代,都是在把“语言的桥梁”筑得更稳更宽。